
GeMEB: Generative Models Empowering Businesses. ID progetto: 11277
L’Area Software Engineering è impegnata in due progetti R&I co-finanziati da BI-REX (Big Data Innovation and Research Excellence): GeMEB e SCAI.

OBIETTIVI.
Il progetto GeMEB si propone di implementare un framework per la consultazione di normative che sfrutti al meglio le potenzialità dei modelli linguistici generativi e le più recenti tecniche di Natural Language Processing (NLP). Lo scopo è quello di fornire uno strumento utile che faciliti, velocizzi e supporti la consultazione delle normative tecniche vigenti. Data la loro importanza e la loro onnipresenza queste normative possono essere molto lunghe e complesse in quanto piene di tabelle, grafici, immagini, e linguaggio altamente specializzato. Queste caratteristiche rende la loro consultazione, in generale, un compito time-consuming anche per utenti molto esperti.
Nello specifico di questo progetto ci concentreremo su una piccola serie di normative vigenti in ambito ferroviario, come le CENELEC e le UNISIG, che vista la loro importanza nell’ambito dei prodotti safety-critical e la loro complessità sono un esempio molto significativo delle difficoltà che caratterizzano questo problema e quindi ci permetteranno di ottenere un framework molto più robusto e più facilmente generalizzabile.
La parte centrale del framework sarà l’attività di ricerca nelle informazioni nel testo partendo da una domanda posta dall’utente attraverso delle tecniche di “information retrieval” tipiche del mondo NLP. Poi queste informazioni dovranno essere “pulite” e categorizzate in modo che solo quelle più pertinenti alla domanda siano usate come input di un modello linguistico generativo, il cui compito sarà “assemblarle” al meglio per fornire una risposta corretta e quanto più possibile simile a quella di una persona in carne e ossa.
Il framework sarà implementato in modo da garantire la massima trasparenza di utilizzo e la privacy dei dati forniti dall’utente. Nello specifico, per ogni risposta ricevuta, l’utente avrà la possibilità di visualizzare le parti del testo usate per generarla e quindi valutarne l’affidabilità. Le informazioni contenute nelle domande, invece, saranno scambiate su interfacce sicure e su una rete locale e potranno essere utilizzati per il continuo miglioramento del framework senza alimentare risorse di terze parti come accade in molte soluzioni presenti on-line.
Nel proseguo della lettura puoi approfondire dagli aspetti tecnici agli sviluppi futuri.
IMPLEMENTAZIONE E RISULTATI.
L’implementazione del framework è stata strutturata su più fasi che hanno sempre previsto una stretta collaborazione tra i designer e gli utilizzatori finali. Il contributo di quest’ultimi, infatti, è stato fondamentale per la fase di selezione del modello linguistico, per l’annotazione di un dataset di addestramento e nella valutazione finale delle performance.
Il modello linguistico scelto è stato Zephyr-7B beta che è rilasciato con licenza open-source garantendo quindi la possibilità di addestrarlo ulteriormente e la completa gestione del flusso dei dati in quanto può essere installato in una workstation in locale. Le normative scelte sono state processate usando una libreria Python chiamata Unstructured che permette di estrarre da file di vari formati sia il testo sia le tabelle. Una volta estratti testi e tabelle sono stati divisi in pezzi più piccoli chiamati chunk e sono stati salvati in un database dedicato. La ricerca in questo database è stata implementata combinando la precisione della ricerca per parole chiave con la potenza della ricerca semantica.
L’addestramento del modello, detto fine-tuning, è stato diviso in due parti. La prima ha previsto come input un dataset creato artificialmente con l’utilizzo di un altro modello linguistico un po’ più grande (Qwen-14B). Lo scopo di questa parte era di far imparare al modello linguistico il linguaggio altamente specializzato tipico delle normative tecnico-ferroviarie. La seconda parte invece ha previsto un ulteriore addestramento utilizzando per un dataset annotato dagli utilizzatori finali. L’idea di questa fase è di allineare al meglio il modello alle richieste degli utilizzatori finali. Per facilitare la creazione di questo dataset annotato è stato implementato un tool apposito chiamato GeDI (GeMEB Data Input) che quindi ha permesso di ottenere un dataset piccolo ma curato in un tempo non troppo lungo e soprattutto in modo standard. Questo tool è indipendente dalla normativa da annotare e quindi potrà essere usato direttamente anche per altri progetti.
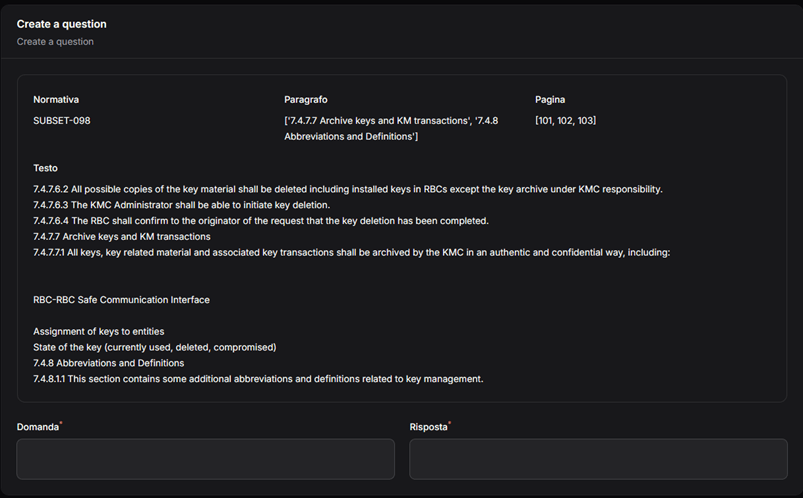
Figura 1 – Esempio di annotazione con GeDI
Dopo l’addestramento il modello è stato messo in comunicazione con i database creati in precedenza e, per facilitarne l’utilizzo, è stata creata un’interfaccia grafica molto semplice da utilizzare. Infatti, l’utente può selezionare la normativa da interrogare, porre delle domande, e valutare le risposte ricevute in modo da avere un feedback aggiornato e un monitoraggio continuo.
Infine, prima di essere messo in servizio, il framework è stato valutato dai dipendenti di MeXage ed è stato modificato in base ai loro commenti e osservazioni.
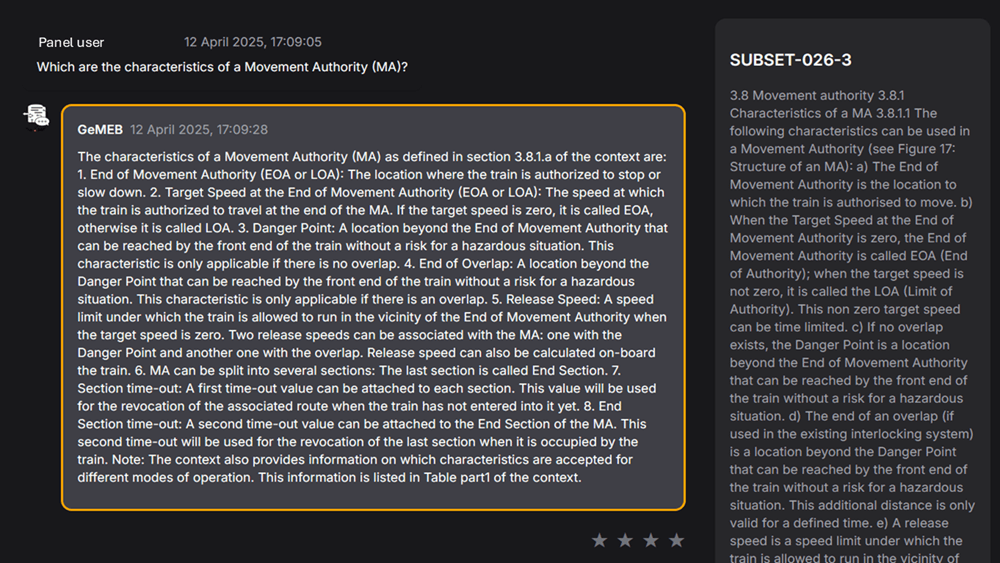
Figura 2 – Esempio di interazione con il framework
PARTNERSHIP E FINANZIAMENTO.
Il progetto è stato co-finanziato dall’Unione Europea nell’ambito del piano NextGenerationEU per un valore di circa 230 mila euro su un totale di 590 mila euro. NIER è la capofila del progetto e fornirà tutte le sue conoscenze in ambito ferroviario, in ambito software e più in generale le sue capacità di innovazione. Inoltre, si avvarrà delle competenze e delle risorse del consorzio BI-REX che è uno degli otto competence center in Italia focalizzato sui Big Data. Gli altri partner di progetto sono il gruppo di intelligenza artificiale (IA) del Dipartimento di Informatica – Scienza e Ingegneria (DISI) dell’Università degli Studi di Bologna e MeXage s.r.l.. Il compito dei primi sarà quello di incorporare nel progetto tutte le loro conoscenze in materia di NLP e IA e le ultime novità della comunità scientifica di settore. Il compito della seconda, invece, sarà quello di utilizzare le loro competenze di sviluppo software in ambito ferroviario per testare le capacità del framework nella fase finale del progetto, valutarne i punti di forza e i punti deboli e fornire feedback per il miglioramento.
SVILUPPI FUTURI.
Tra gli sviluppi futuri, oltre al continuo aggiornamento del framework si sono la sua applicazione a normative in altri ambiti come il trasporto di sostanze pericolose (ad esempio la ADR), la gestione dei grandi rischi (D.Lgs. 105/2015), la classificazione delle sostanze pericolose (ad esempio la REACH) e la tutela ambientale (D.Lgs. 152/2006). Il progetto, quindi, rappresenta solo il primo passo verso un progetto trasversale di grande utilità in molti ambiti tecnici.

ID progetto: 11277